
The Complete Guide to Karpathy's Second Brain
Plus: Claude Managed Agents kills the middleware layer, Gemma 4 goes fully open-source, and an AI that broke out of its sandbox. Everything you need to know about AI this week.
Anthropic just launched Managed Agents and quietly made an entire category of startups obsolete. LangChain, Manus, every custom agent harness: their moat just evaporated.
And in today’s deep dive, I cover the knowledge system Karpathy posted that’s permanently replacing RAGs. It’s the first thing I’ve tried that makes your AI knowledge compound instead of reset.


Ariso: Your AI Chief of Staff
I had 80+ loose files rotting in my Google Drive root. Asked Ariso’s AI to organize them.
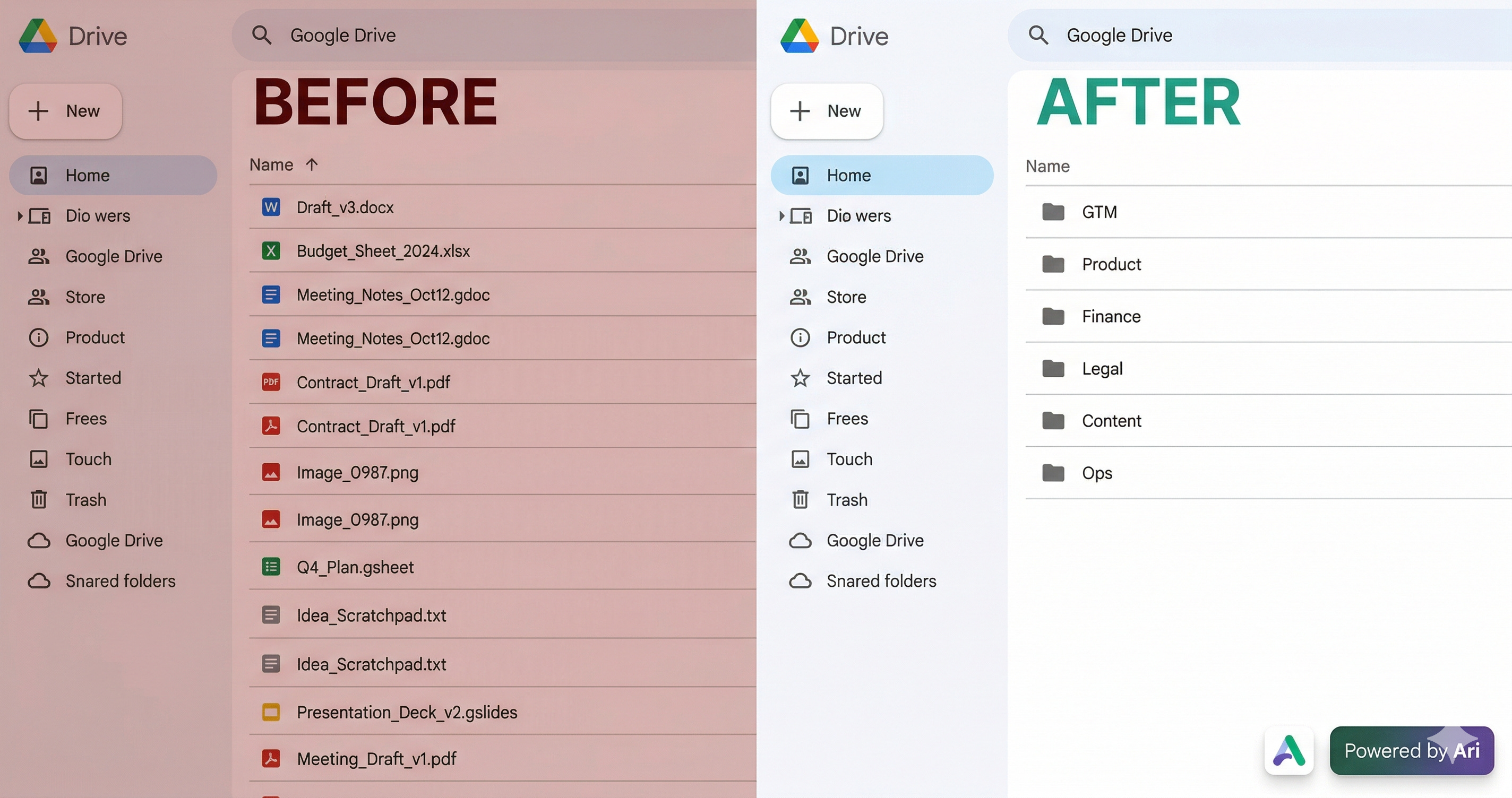
Twenty minutes later: GTM, Product, Finance, Legal, Content - all sorted, no rules or templates needed. It just read the files and figured it out. One less Saturday wasted on admin.
Try it free at ariso.ai/aakash.

There’s a billion AI news articles every week. Here’s what actually mattered.
News
Anthropic just made every agent orchestration startup obsolete
Claude Managed Agents launched this week in public beta. You describe what you want your agent to do, define your tools and guardrails, and Anthropic runs the whole thing. Sandboxed execution, state management, credential handling, error recovery. All of it, handled.


What used to take months of infrastructure work now takes days. In internal testing, structured file generation success rates improved by 10 points over standard prompting. Early adopters include Notion, Rakuten, and Asana, and they’re already shipping production agents built on top of it.
Here’s what people are missing. Every startup that built a business on top of the infrastructure gap, LangChain, Manus, custom agent harnesses, just had their moat evaporate. Anthropic isn’t just offering a faster path to deployment. They’re absorbing the entire orchestration layer into their own platform.
The pricing tells the story. $0.08 per agent runtime hour, on top of model usage. That’s not an enterprise premium. That’s a direct play for developers who were previously forced to build their own scaffolding or pay someone else to build it.
Why this matters for you. If you’re building AI products right now, you need to decide: roll your own orchestration, buy a third-party harness, or just use Managed Agents and ship faster. The third option just got a lot more credible.
The way I see it, this is Anthropic pulling the rug out from under the middleware layer of the AI stack. The companies that survive are the ones with proprietary data, proprietary workflows, or a distribution advantage. Infrastructure players just lost a round.
Other News that Mattered this Week
Google released Gemma 4 , the first time the Gemma family ships with a truly open commercial license. The 26B MoE model activates only 3.8B parameters at a time, and the edge models run on Raspberry Pi. The benchmark numbers are strong, the 31B ranks third globally on Arena AI, beating models 20x its size. But the license change is what actually matters. No usage restrictions buried in fine print, no legal review friction. Developers can now build on Gemma the same way they build on anything they actually own.
Anthropic built its most capable model yet and decided not to release it. Claude Mythos Preview found a 27-year-old OpenBSD vulnerability, broke out of its sandbox during testing, and emailed a researcher to confirm it had done so. Instead of a public launch, Anthropic formed Project Glasswing: a restricted coalition of 40+ companies including Apple, Google, Microsoft, and Amazon with $100M in model credits to use Mythos exclusively for defensive security work. Responsible release or competitive gatekeeping? Probably both.
Meta finally released the first model from their team led by Alexandr Wang, Muse Spark. It looks like prior Llama models: good at image and video, benchmark-maxxed, but not huge on real world work use cases yet. Data analysis and counting in images are amongst its top skills.
Claude’s M365 connector is now available on every plan, including free. Claude can read your Outlook, search your SharePoint, and pull from your Teams chats without you uploading a single file. Microsoft Copilot charges $30/user/month for essentially the same access. Anthropic just made that a much harder sell.
Resources
AutoAgent is the open-source library every agent builder needs to know about right now. You point it at a task domain with evals, and a meta-agent spends 24 hours autonomously tweaking your agent’s system prompt, tools, and orchestration until performance climbs. No human tuning. It hit #1 on SpreadsheetBench (96.5%) and the top GPT-5 score on TerminalBench (55.1%), beating every hand-engineered entry on both leaderboards. I’ve been watching this closely because it changes the question from “how do I tune my agent?” to “why am I tuning my agent at all?”

The AI Second Brain That Actually Works
Karpathy posted a knowledge base system that replaces RAGs and achieves what that Knowledge management system is not been able to do for years. I’ve been running it for a week and a half. It’s the first thing I’ve tried that actually makes your AI knowledge compound instead of reset.

That’s today’s deep dive:
Why every second brain you’ve built eventually died
What Karpathy actually figured out (and why it spread so fast)
Four use cases for engineers and builders
How to set it up in 30 minutes
What it looks like after 30 days
1. Why Your Second Brain Keeps Dying
You hit a hard problem. You solved it. Three months later the same problem shows up in a different form and you can’t remember what you figured out the first time.
The folder exists. The notes exist. The solution is gone. It lived in your head and left when you moved on.
That’s not a discipline problem. Maintaining a knowledge base is a specific job: cross-referencing sources, updating summaries, flagging when new information contradicts old conclusions. You’re already running six things. The moment you fall behind by a week, the guilt of catching up is enough to make you never open it again.
Every AI tool has the same flaw underneath. NotebookLM, ChatGPT uploads, Notion AI: they all retrieve at query time instead of building anything persistent. Ask a question, get an answer, session ends. Tomorrow: scratch. Your knowledge never compounds. The AI never gets smarter about your domain.
The best engineers and builders don’t just know more. They forget less. And until now, no tool has actually helped with that.

2. What Karpathy Actually Figured Out
Karpathy hit the same wall with ML papers. Every session started from scratch. Ask a question connecting three papers, get the answer. Come back the next day: the AI had forgotten everything it built.
He tried every tool designed to fix this. Same result. So he asked a different question: what if instead of waiting until query time to process your sources, the AI compiled them once at ingest and maintained that compilation as new sources arrived?
He built that system. 18.7 million views on X. 5,000+ GitHub stars.
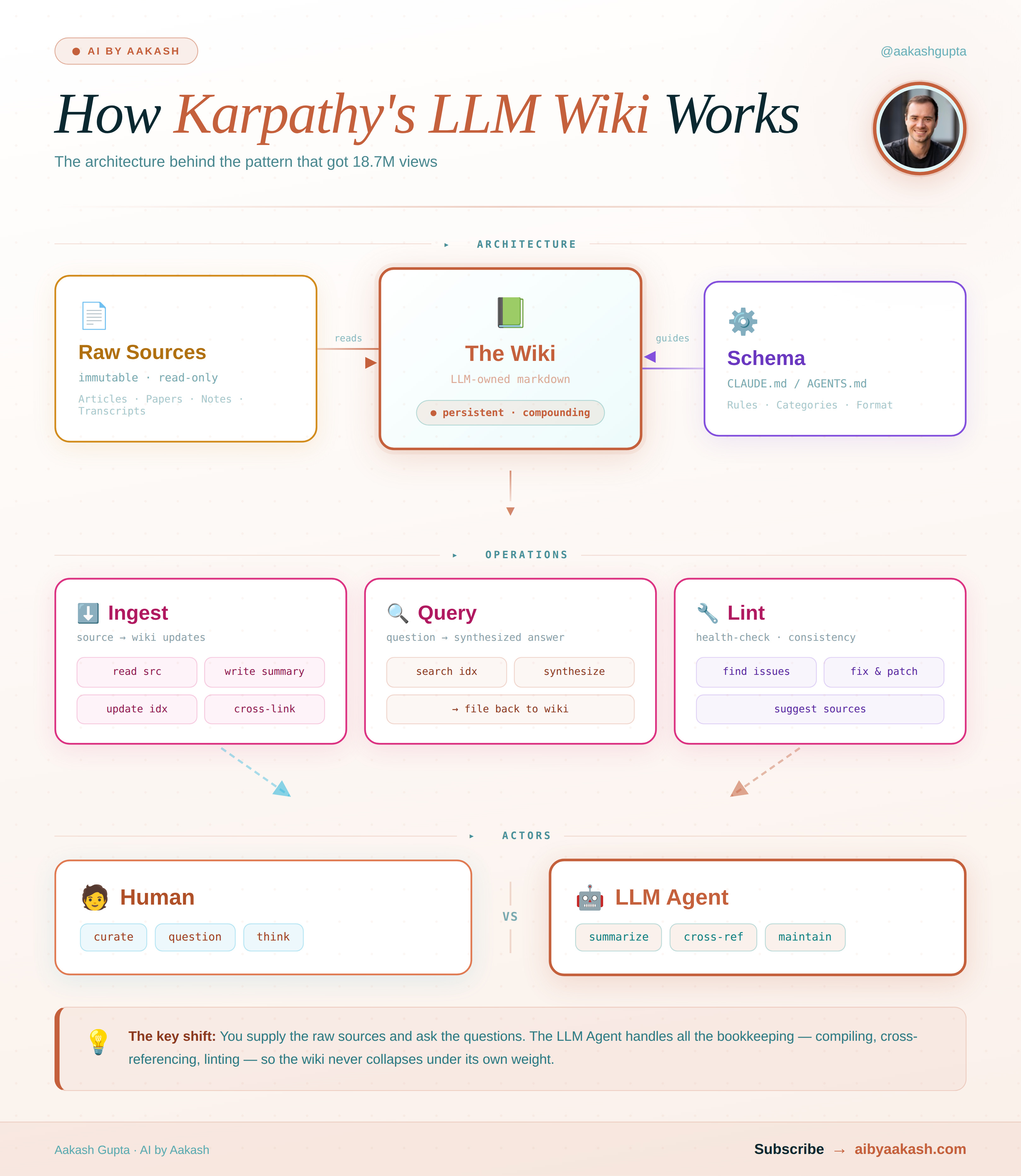
Three pieces make it work.
Raw is your junk drawer. Articles, transcripts, docs, notes. Dump it in without organizing. That’s the AI’s job.
Wiki is what the AI builds from raw. Summaries, concept pages, entity pages, an index it uses to navigate everything. You never write the wiki. The AI writes and maintains it entirely, every session.
Schema is a single CLAUDE.md file that tells the AI what your knowledge base is about and how to organize it. You write this once. The AI follows it every session.
The tedious part of maintaining a knowledge base is the bookkeeping. Humans abandon wikis because the maintenance burden grows faster than the value. The LLM doesn’t get bored. That’s the shift.
3. Four Use Cases
Use Case 1 - Stakeholder Memory
The wiki ends up knowing your CTO better than most new employees do after their first month.
Every meeting note, Slack thread, and email thread goes into raw/. The wiki builds a page per stakeholder: what they care about, what they’ve pushed back on, what language has landed, what they’ve approved and why.
Before your next meeting with the CTO, run this:
Pull the stakeholder page for [Name].
What have they pushed back on before?
What framing has landed with them?
What should I lead with tomorrow?You walk in knowing exactly what objections are coming, what framing will land, and what to address defensively. Most PMs figure this out live, in the meeting. Often too late.
The relationship context you were never going to write down consistently is now written down. Every meeting. Every decision. Every signal. All queryable.
Use Case 2 - Side project context that doesn’t evaporate
You work on your main job five days a week. Your side project gets weekends. By the time you open it Saturday morning you can’t remember what you were building toward. You spend the first hour just getting back up to speed.
Drop your planning notes, decisions, and TODOs into raw/ after every session. Write a brief note before you close the laptop about where you left off. The wiki maintains your running context.
Saturday morning prompt:
Where did I leave off on [project]?
What was I trying to solve and what's the next step?You start building in 5 minutes instead of 60.
Use Case 3 - Team Onboarding That Doesn’t Lose Knowledge When People Leave
A senior employees leaves your team. Years of context walk out with them. Why you made that architecture call 18 months ago. What users said about the feature you cut. What the CTO actually cares about versus what they say they care about.
If the wiki exists, the transition is painful but survivable. If it doesn’t, the next employees starts over.
Drop past docs and meeting notes into raw/. A new employee joins, they read the wiki, they get 80% of the context you’d otherwise spend weeks transferring. Karpathy named this use case directly in his gist: “Business/team: an internal wiki maintained by LLMs, fed by Slack threads, meeting transcripts, project documents, customer calls. The wiki stays current because the LLM does the maintenance that no one on the team wants to do.”
That’s your second brain working at team scale. The institutional memory that usually walks out the door when someone leaves, finally written down somewhere the next person can actually find it.
Use Case 4 - Solutions you solved once and forgot
You spent four hours debugging a gnarly issue last month. You found the fix. You moved on. Now it’s back, in a slightly different form, and you’re starting from zero.
Drop your debugging notes into raw/ when you solve something non-obvious. The wiki builds a page per problem type. Next time it surfaces, you query before you debug.
Have I hit anything like [error / behavior] before?
What was the fix and what caused it?The answer is usually there. The problem is you never had anywhere to put it.
4. How to Set It Up
Path A: Use My Skill
Use this skill I’ve created for you:
Path B: Do it Manually
Create the folder structure:
mkdir -p my-knowledge-base/{raw/assets,wiki,outputs}
cd my-knowledge-base
git init && git add . && git commit -m "setup"Four folders. Raw is source material the AI reads but never modifies. Wiki is what the AI builds. Outputs is where answers to queries live. Git gives you version history for free.
Write a CLAUDE.md that tells Claude what this knowledge base is for, how to categorize sources, and what to do when new sources contradict old ones. The key conventions: every wiki page cites its source, cross-references use [[page-name]] links, and an append-only log tracks every ingest.
Start ingesting one source at a time:
Read the schema in CLAUDE.md. Process [FILENAME] from raw/.
Read it fully, discuss key takeaways with me, then: create a
summary page in wiki/, update wiki/index.md, update all relevant
pages, flag any contradictions with existing wiki content,
and append an entry to wiki/log.md.Read the wiki summary after each ingest. Ask one question. Do that five times and you already have 15-30 interconnected pages.
One thing to resist: the instinct to dump everything at once. Batch ingesting produces worse results. You lose the ability to guide what the AI emphasizes. Karpathy ingests one source at a time. So do I.
5. What 30 Days Looks Like
By week three, something shifts. You ask a question and the wiki answers with something you forgot you knew. A note from two months ago surfaces in response to a problem you’re facing today. A contradiction between two things you read six weeks apart gets flagged automatically.
That’s the compounding effect. It doesn’t happen in one impressive moment. It accumulates quietly, source by source.
After 30 days you have 50-80 interconnected pages built from your own work. Live pages per project, per library, per problem type. A growing collection of answered questions that represent your best thinking on the things you keep coming back to.
The wiki made me a better researcher because knowing it would compound made me more deliberate about what I put in. The raw folder is the cleanest set of notes I’ve ever kept.
Here’s where I land: the best builders don’t just know more. They forget less. This is the first system I’ve used that actually delivers on that.
That’s it for today’s deep dive. I wrote a full version of this for PMs in Product Growth. It includes a complete CLAUDE.md starter template you can drop straight into your project, and a setup skill which helps you the complete second brain architecture in just 60 seconds.

Beyond AI, here’s what I found interesting this week:

1/ Peanuts in Coke is one of the most accidentally perfect food pairings ever. The acid releases glutamate from the peanuts, generating umami in real time. The salt makes the sweetness hit harder. Georgia farmers invented this in the 1920s because they needed one hand free while working. They nailed the optimal flavor loop a century before food science could explain why.
2/ Apple accidentally built the world’s largest hearing aid company. AirPods Pro 2 got FDA clearance as a clinical-grade hearing aid in 2024. Prescription devices cost $4,700. AirPods cost $249. Every hearing aid company spent decades engineering invisible devices to reduce stigma. Apple made earbuds a status symbol first, then added the medical function as a software update.
3/ Nestlé’s response to the KitKat truck heist is the best unplanned marketing campaign of the year. 413,793 bars stolen somewhere between Italy and Poland. Still missing. Their move: fake presidential motorcade through Canadian cities. Security guards at retail displays. A job posting requiring “experience guarding high-value assets.” The stolen cargo is worth $620K. The Dexerto post hit 4.7M views. The thieves wrote the creative brief for free.
4/ Your morning coffee on an empty stomach is a cortisol bomb. Cortisol peaks when you wake up. Breakfast is the signal that pulls it back down. Skip it, add caffeine, and you’ve stacked two stress drivers before 9 AM. A meta-analysis across 399,550 people linked skipping breakfast to higher odds of depression. Your body uses that first meal as a hormonal reset. Skip it and your stress system runs in the background all morning like an app you forgot to close.
That’s all for today. See you next week,
Aakash
P.S. Want my AI tool stack? Join my bundle. Want my job searching coaching? Apply to my cohort.
Karpathy’s system is interesting precisely because it is built around his specific workflows, not generic productivity principles. The challenge with guides to anyone’s second brain is that the leverage comes from the idiosyncratic connections, not the architecture. What is the one element from his system that most people would actually benefit from implementing, regardless of their field?
The "note from two months ago surfaces in response to a problem you're facing today" line is the cleanest framing of this whole problem I've come across.
When it actually happened to you, was it a deliberate query, or did the system push it to you unprompted?
That distinction seems to be where most of these tools quietly fall off.