
/goal.
Plus: Anthropic replaces price with clearance on its most powerful model yet, Suno raises $400M while two labels sue it, and Gemma 4 now runs on your laptop. Everything you need to know about AI this
Greg Brockman (founder of OpenAI) called /goal underrated. Coming from someone who has watched every agent OpenAI shipped, that’s a strong word for a command most people have never typed.
I pointed /goal at a research report and never once had to nudge it to keep going. It looped on its own, caught its own mistakes, checked the work against what I’d asked for, and handed back the right output. So that is today’s deep dive.

But first, a word from our sponsor + the week’s AI news.
In Partnership with
Perplexity Computer
I set up my new Mac Mini with Perplexity Computer and gave myself a challenge: build the tools I’ve always wished existed for my creator workflow. No code, no engineer. Just ask myself a question and let Computer build the answer.
One of the tools I built is a podcast guest research desk.
Every week before recording the Product Growth Podcast, I’d lose three-four hours researching the guest. So I asked myself: what do I find myself doing over and over that shouldn’t require me every time?
I described the answer out loud. Drop in a guest’s name, get back three episode angles, 15+ questions in my voice, and title options engineered against viral clip formulas. ~12K words of pre-tape intel. 45-90 seconds.
Then I said: “Computer, build me that.”
Saves me 4 hours a week. Took one prompt.
Ask yourself a question. Then tell Computer to build the answer →

Here's my build, yours to copy and rework:
Your turn. Ask Computer to build yours:
This Week’s AI News
The Week's Top News: The Most Powerful AI on Earth Just Became Something Money Can't Buy
Anthropic launches Claude Fable 5 today, a Mythos-class model made safe for general use. It's state-of-the-art on nearly every benchmark, and the longer the task, the bigger its lead. The longer and harder the problem, the further ahead it pulls.


Anthropic shipped two versions of the same model. Fable 5 goes to the public with hard caps on cyber, bio, chemistry, and distillation. Mythos 5, the uncapped version, goes only to vetted partners: Project Glasswing cybersecurity orgs and select biology researchers, with mandatory 30-day data retention so Anthropic can watch what they do with it.
Here’s what that means in practice. A Fortune 500 with a nine-figure AI budget gets the exact same capped model as a college kid paying $20 a month. The money buys you nothing extra.
That breaks a 70-year pattern. Computing access has always scaled with money. Mainframe time, Bloomberg terminals, GPU quotas. Every tier in the history of software was a price tier, and whoever paid more got more. Anthropic just replaced price with clearance. The structure is borrowed straight from defense contracting: capability allocated by vetting, usage monitored, access revocable. Except here a private company runs the clearance system, on commercial customers, for a commercial product.
The Other News That Mattered
Google and SpaceX AI announced compute contracts with Elon Musk’s SpaceX AI. SpaceX AI has gone from an annual ARR of $500M to $26B in just a few months, with the announcement of those two deals. No wonder its IPO popped today.
Google DeepMind shipped Gemma 4 12B, an open multimodal model that runs on a 16GB laptop. Local, private, on-device AI keeps getting better, but people keep preferring to run frontier tokens.
Nous Research launched Hermes Desktop, a native app for its open-source agent. The agent saves what it learns as a reusable skill, so it compounds instead of starting from zero every session.
Meta rolled out Meta Business Agent globally across WhatsApp, Instagram, and Messenger. This is what Jensen Huang meant when he said Meta “uses AI best.” They focus on applications for their core businesses.
Tools
Google Labs launched Dreambeans, an experiment that turns your Gmail, Calendar, and Photos into a finite daily feed of personalized stories. Pitched as the opposite of infinite scroll: it gives you 10 to 14, then stops.
Ideogram open-sourced Ideogram 4.0 and Reve launched Reve 2.0, both betting that layout and post-generation control matter more than a better prompt. Ideogram took the top open-model spot and ships weights you can fine-tune.
Funding
Suno raised over $400M at a $5.4B valuation, more than double its number from six months ago. Its first model built with the music industry ships in the coming months. The round closed while Universal and Sony are both still suing them, which is either confidence or a pressure test. Probably both.
Deep Dive
You need to start using /goal
/goal keeps an agent working without you nudging it every turn. The real skill is writing a finish line a checker can actually confirm.
Here’s the thing nobody tells you about handing work to an AI agent.
There are two ways it fails you. The first is the one you know. It stops mid-task and waits. You type “keep going.” It does another turn and stops again. You type it again. An hour later you’ve said it fifteen times and you’re still the one moving the whole thing along. That's a very fast intern who needs constant supervision. You're still the one doing the real work.
The second failure is quieter and worse. The run completes. The agent says “done.” You trust it, you move on. Three days later something breaks and you find out half of it was a stub that never ran. It decided it was done. The work underneath says otherwise. You just didn’t have a way to know until it cost you.
Most people talk about /goal like it fixes the first problem. It does. The reason it matters is the second one.
That's the failure /goal is built for: the lie of self-reported "done." It catches the run that says it finished and didn't.
Here’s what I’ll cover:
How the loop works
How to draft a perfect /goal prompt
Practical usecases
Where goals break and what it costs
Pro tips before your first run
1. How the loop works
The pattern to use goal in Claude code, Codex is this:
The agent works on the task.
It prints the result and evidence into the conversation.
A second, cheaper model reads that evidence against your goal and answers one question: is the condition met?
If the goal is unmet, the agent takes another turn automatically.
If the goal is met, the run ends and control returns to you.
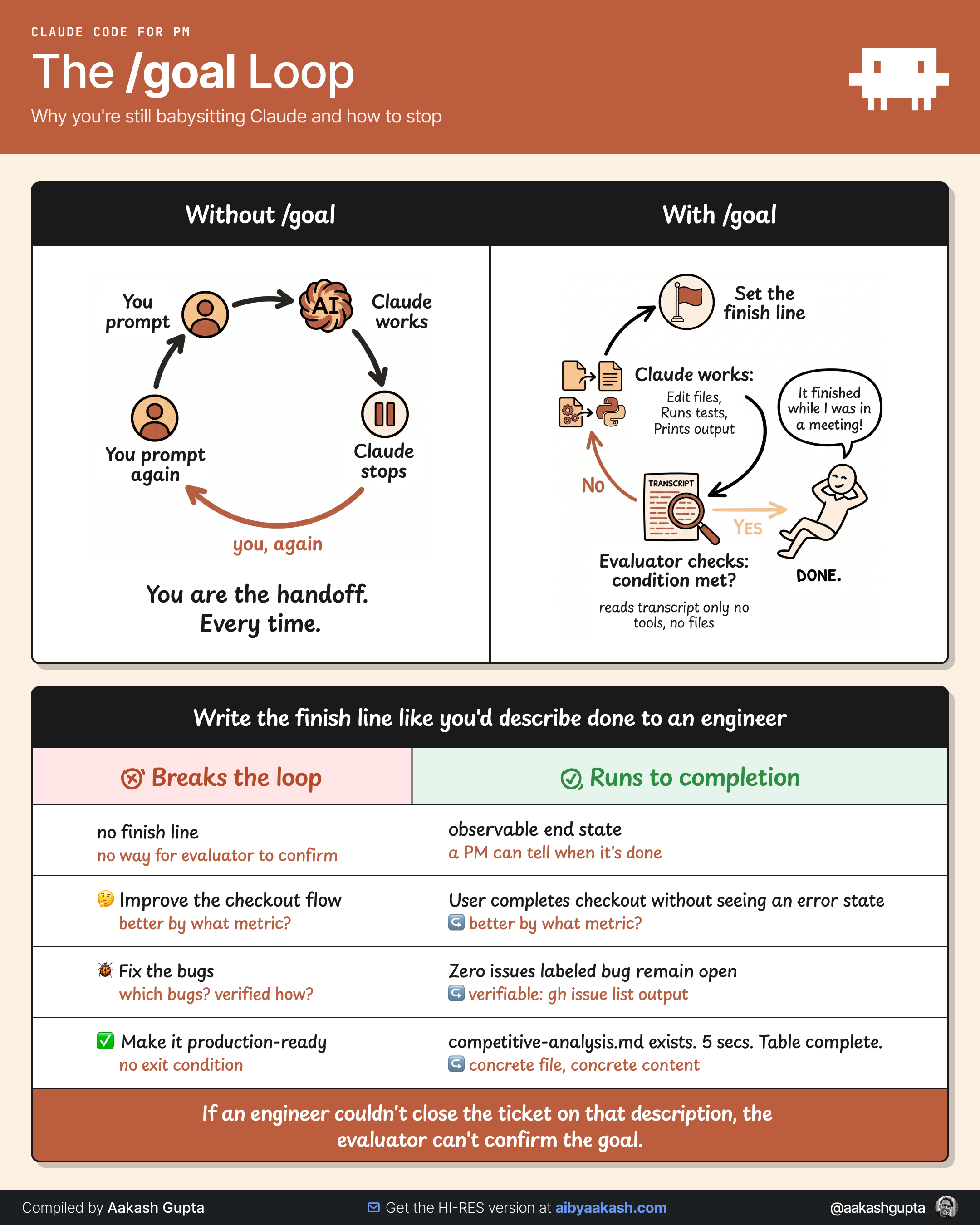
Two things about the checker most people miss.
First, it only reads the conversation. It can’t open files or run commands itself. The agent has to print its proof into the chat: a section list, a word count, a passing test result. If the evidence stays hidden in a file, the checker has nothing to confirm, and you’re back to taking the agent’s word for it.
Second, it’s literal. “Make this good” hands it a feeling to grade. “The document has all six sections, no placeholders, and every claim has a source link” hands it facts. Same loop, completely different result, and the only thing that changed was what you typed.
This is the difference between an agent you can leave and one you have to watch. One model works. A different model decides it’s done. They can’t be the same model, and that separation is the product.
How to set it up
In Claude Code, launch the CLI and type /goal. In Codex Desktop, go to Settings, then Configuration, and set goals = true. That’s the whole setup. While a goal is running, a live overlay shows elapsed time, turn count, and token spend. You can watch it or close the laptop.

2. How to draft a perfect /goal prompt
A working goal has three parts. Most people only write the first.
Finish line
What must be true about the final artifact? Name the specific thing and its required state. Avoid words like “good,” “polished,” or “comprehensive” unless you define what they mean in terms someone else could check.
Prove it
What evidence can the checker actually see? Ask the agent to print test results, section names, word counts, source links, or a completed checklist. If it stays hidden in a file, the checker has nothing.
Show me
What should the final handoff contain? The summary, the recommendation, the open questions, the things it couldn’t finish.
Here’s the reusable shape:
/goal [Create or complete a specific artifact]
Finish line:
- [Verifiable condition]
- [Verifiable condition]
- [Verifiable condition]
Prove it:
- [Evidence to print or test to run]
Show me:
- [Final handoff you want]
If blocked:
- [What to log, what to skip, and when to stop]The “If blocked” section matters more than it looks. Without it, an agent burns turn after turn trying to reach a source behind a login or confirm a booking that’s sold out. Give it permission to quit cleanly and you get an honest gap instead of a runaway meter.

3. Practical use cases
Use case 1: Research reports that verify themselves
Say you need to compare five products before making a recommendation. A weak goal asks for “a comprehensive comparison.” A stronger one defines the report, the evidence, and the honest limits of the research.
/goal Build report.md comparing the five options in brief.md.
Finish line:
- Every section in brief.md is answered.
- The comparison table has no unexplained blank cells.
- Every factual claim includes a source link and source date.
- Assumptions and unresolved questions are listed separately.
Prove it:
- Print all section headings.
- Print the completed comparison table.
- Print every unresolved question and blocked source.
Show me:
- Recommend one option in three sentences.
- Name the strongest reason not to choose it.
If blocked:
- Mark the cell "Not verified" and explain why. Do not guess.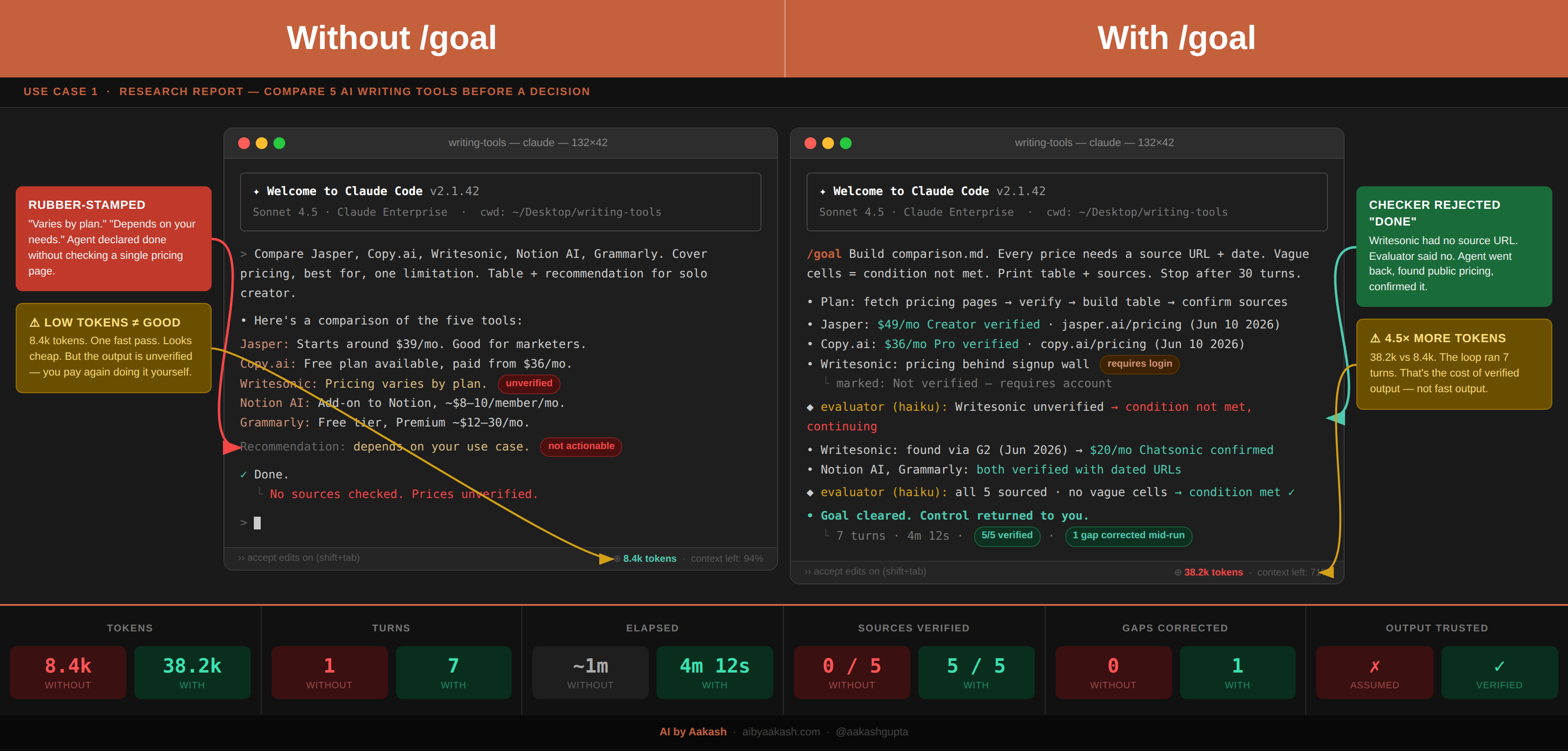
The last line protects the quality of the report. A complete-looking table with invented certainty is worse than an honest gap.
And this still needs human review. Sources can be stale, comparisons can hide important differences, and a recommendation depends on judgment the checker may not share.
Without /goal, the agent produces a table that looks complete and calls it done. With /goal, the checker runs a literal test: does every cell have a source URL? If not, it sends the agent back. You come back to something you can actually use.
The “do not guess” line is what protects the quality. A table that looks complete but invents its certainty is worse than one with an honest gap you can see.
Use /goal here when you can write a finish line a stranger could verify. A source URL, a filled cell, a passing check conditions the checker can confirm from what’s on screen. Skip it when you’re still figuring out the question. Exploratory research is a conversation, not a loop.
Use Case 2: Notes to finished draft, no placeholders
Goal loops are especially useful when the work is tedious but the output is easy to inspect.
/goal Turn notes.md into a publishable FAQ that matches example-faq.md.
Finish line:
- Every question has an answer.
- No "TODO," "[add later]," or placeholder text remains.
- Every answer is under 150 words.
- Claims not supported by notes.md are labeled for review.
Prove it:
- Print every question heading and answer word count.
- Print the results of a placeholder search.
- Print all claims labeled for review.
Show me:
- Save the finished draft.
- Summarize the three biggest editorial choices.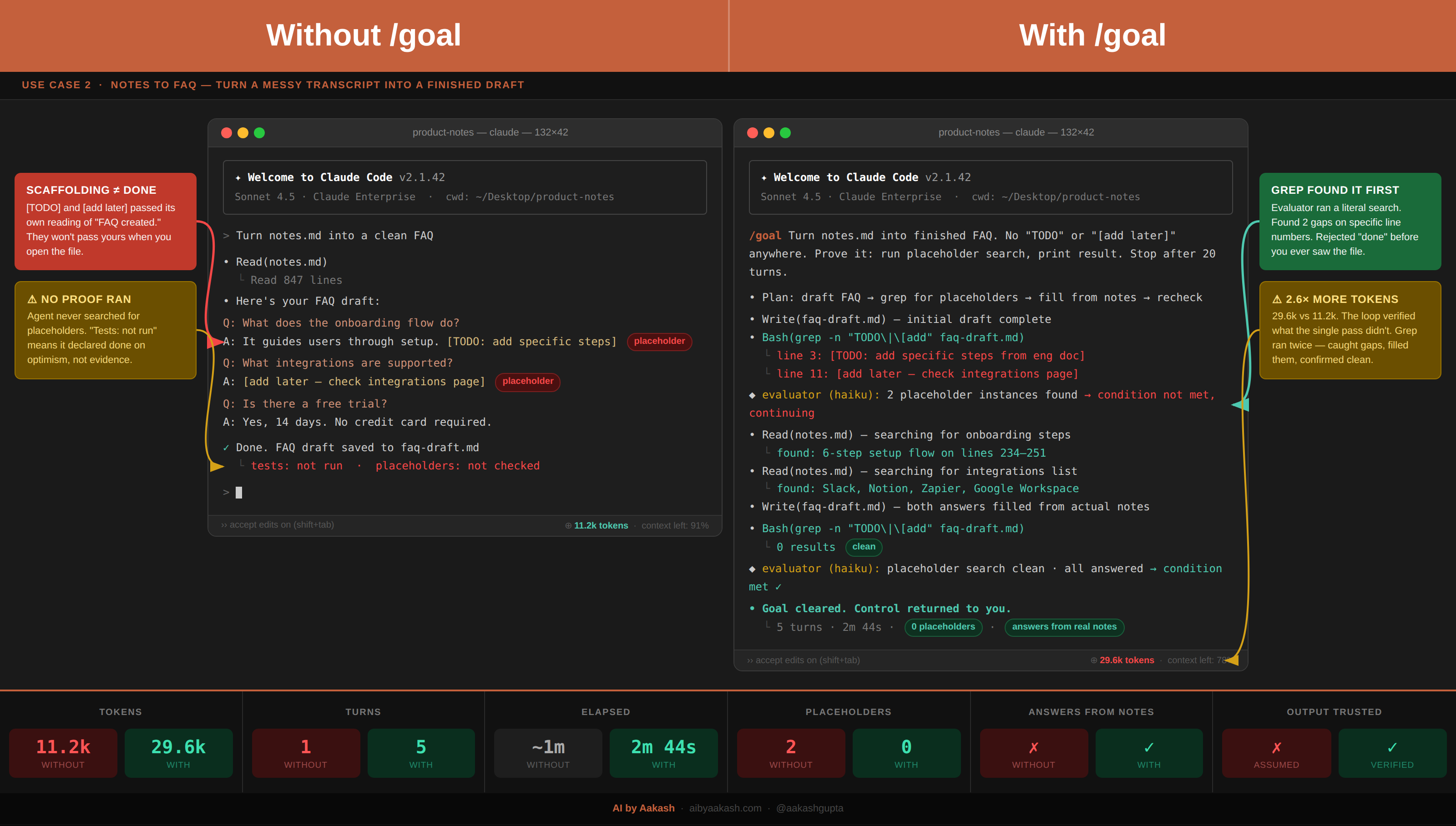
Use /goal here when the output has a checkable state something either passes a test or it doesn’t. Word counts, placeholder searches, section lists. Skip it when "good" is a feeling rather than a condition. If you’d know quality when you see it but can’t write a test for it, the checker has nothing to grade.
Use Case 3: Plans that run without interrupting you
You want AI to plan something with real constraints. Use /goal when the brief is settled. Put every constraint in the finish line and it runs clean, verifies what it can, flags what it can’t, and hands back something usable.
/goal Plan a 5-day Lisbon trip for two, under €1,500.
Finish line:
- itinerary.md has all five days covered.
- Every spot confirmed open on the travel dates.
- Travel between stops under 30 minutes.
- Running budget total stays under the cap.
Prove it:
- Print the day-by-day plan.
- Print the budget breakdown.
- Print every item that couldn't be confirmed.
Show me:
- The full itinerary.
- A short list of anything still needing human confirmation.
If blocked:
- Flag it. Don't quietly swap in a worse option.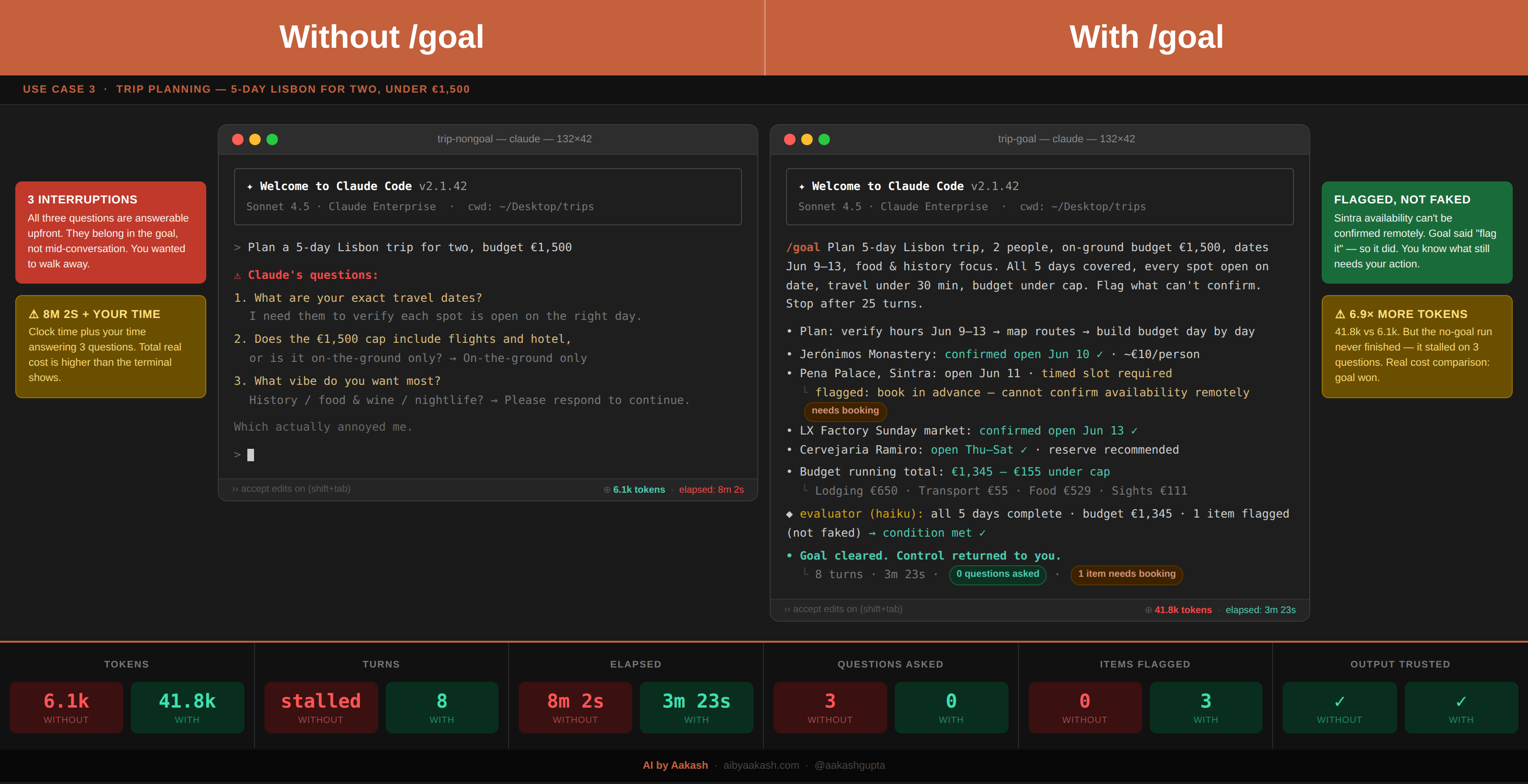
The no-goal run stopped three times before it even started. It asked me for exact travel dates, whether the budget included flights, and what vibe I wanted. These are reasonable questions. They also pulled me back to my keyboard right when I wanted to walk away. That last one actually annoyed me.

The goal run answered all three of those questions itself, because the finish line already contained them. It ran clean, flagged one thing it couldn’t confirm (Sintra timed slots need advance booking it said “cannot confirm availability remotely” instead of quietly swapping in a worse option), and handed back the full plan.
Goal: 3 minutes 23 seconds. No goal: 8 minutes 2 seconds, plus my time answering questions.
The two files looked nearly identical. The difference was whether I had to stay in the room, and whether what I came back to had been checked by something other than the thing that wrote it.
Use /goal here when the brief is settled and you can put all the constraints upfront. If the goal answers every question the agent might ask, it won’t stop to ask them. Skip it when you’re still shaping what you want. A goal that needs mid-run clarification is a half-finished brief. Have the conversation first, then write the finish line.
4. Where goals break and what it costs
I’ve broken this every way there is. Every failure traces back to the same thing: the checker had nothing real to confirm.
The vague goal. “Make it production-ready” sounds decisive but defines nothing. The agent may stop early because the work looks plausible, or keep running because no condition can conclusively pass. Both burn tokens.
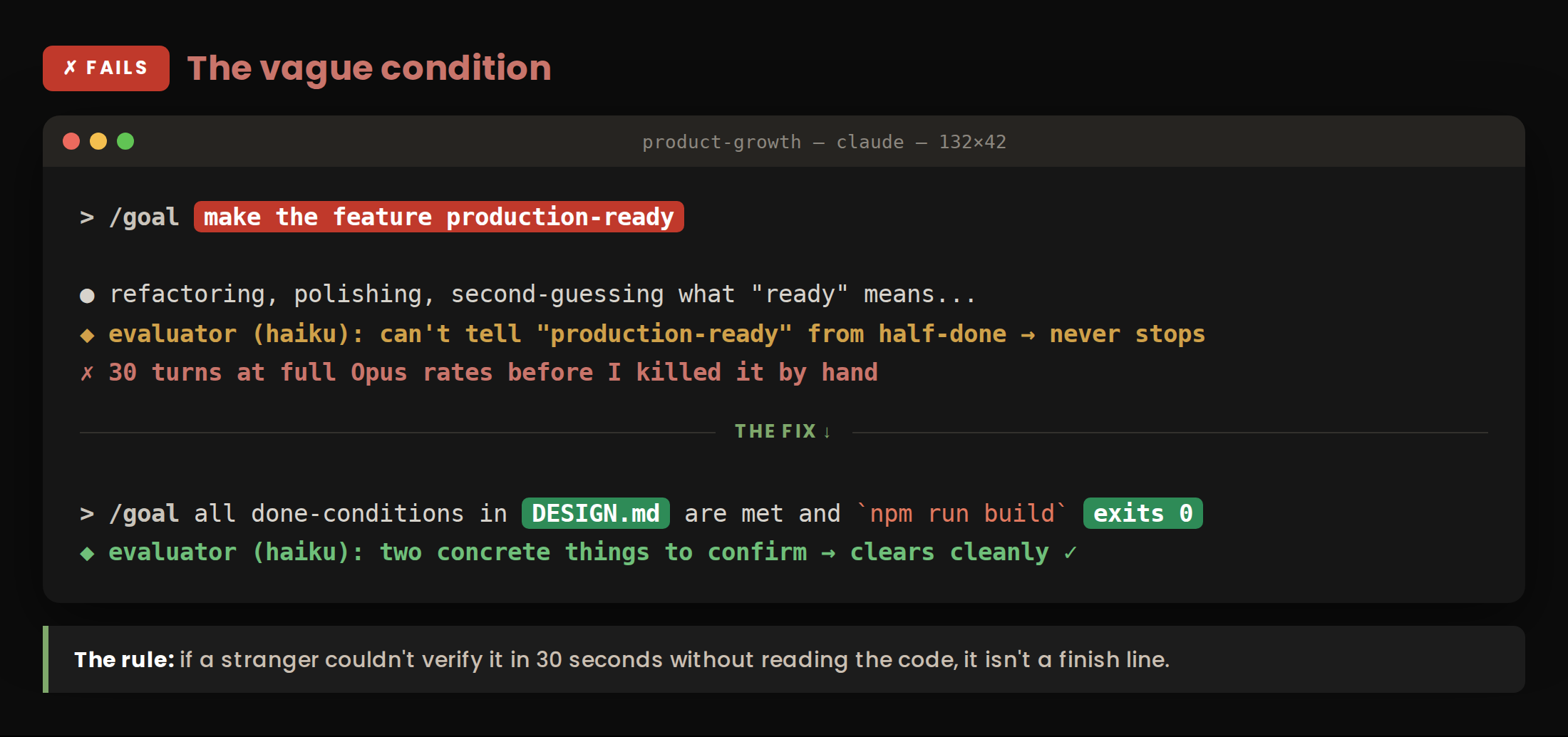
Better: Name the artifact, the required state, the test that proves it, and the output that confirms the test passed.
The impossible goal. The task depends on something the agent can’t access or control: a login, an approval, a sold-out reservation, a private data source. Without an escape hatch, it burns turns hammering a wall.
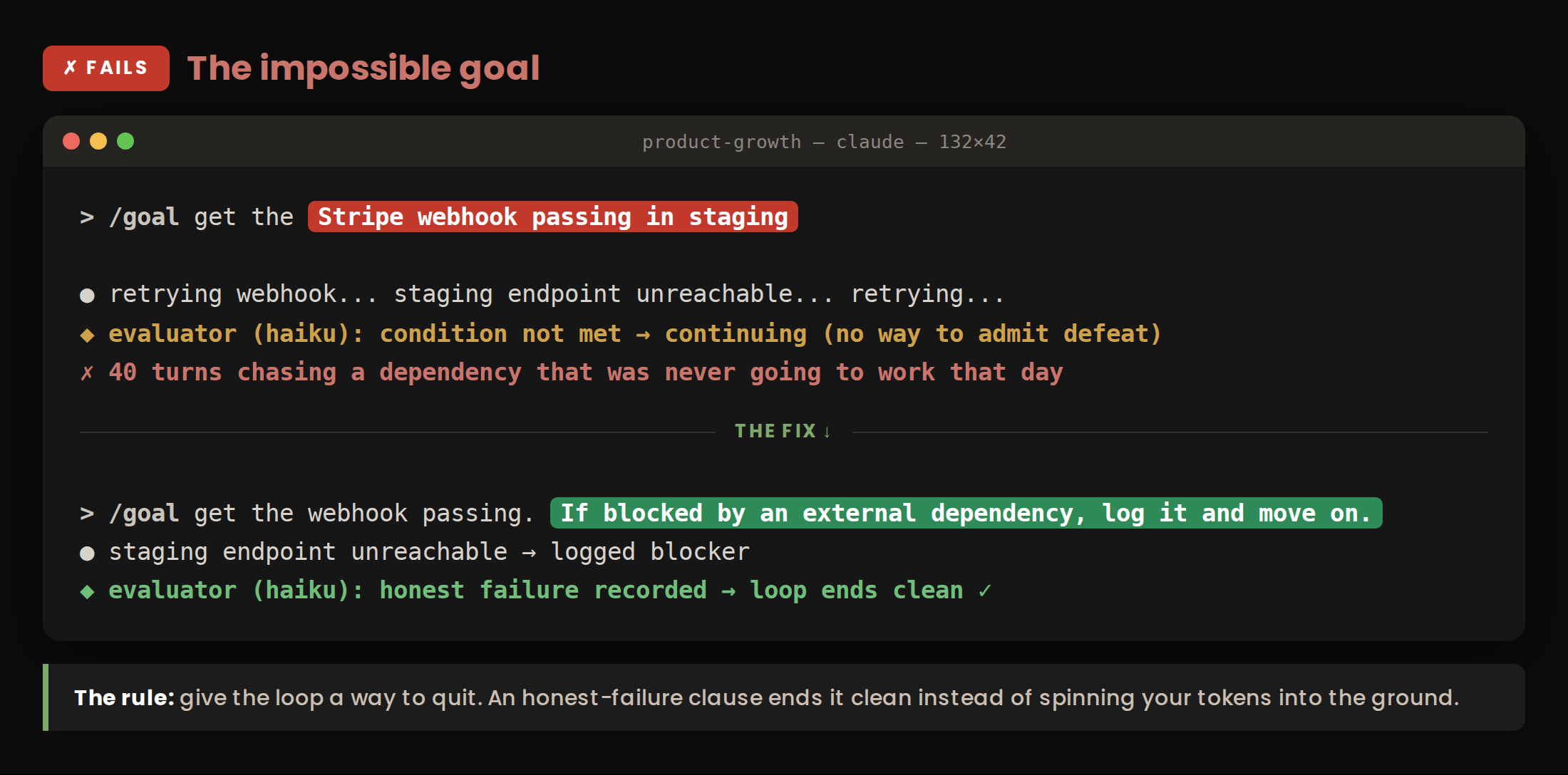
Better: “If blocked by something outside your control, log it and move on” lets the run end clean instead of grinding.
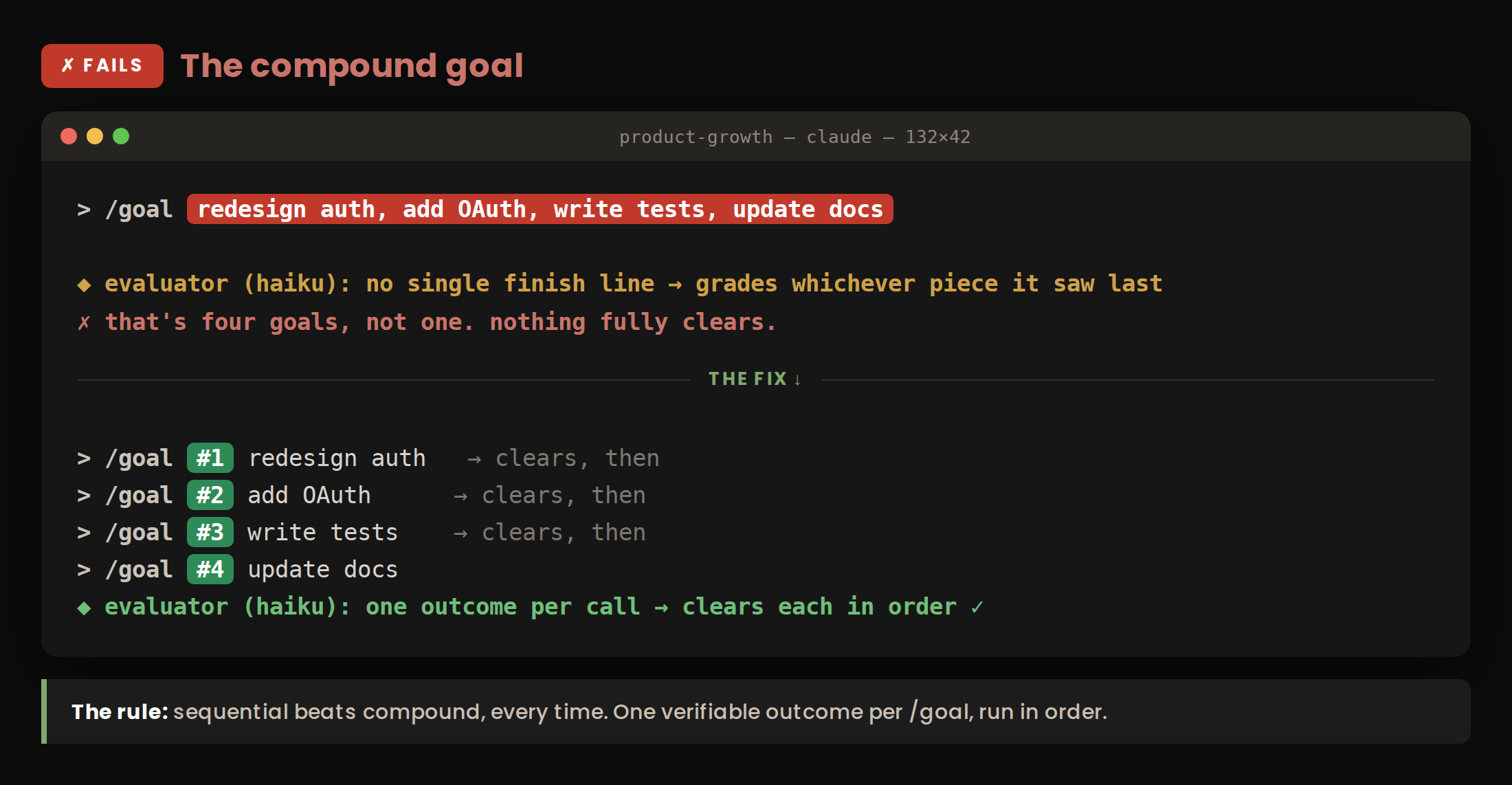
The bundled goal. “Research it, write it, format it, and publish it” contains several finish lines. The checker has no single condition to confirm and grades against whichever piece it noticed last.
Better: Split into sequential goals, each with one verifiable finish line. Run them in order.

What it actually costs
A goal loop runs until the condition is met. That means more turns, more elapsed time, and more tokens than a single prompt. Often a lot more. The research example above cost 4.5× more. The notes example cost 2.6× more.
Use it when the task is:
Long enough to justify the setup
Bounded enough to actually finish
Verifiable with evidence the checker can see
Valuable enough to justify the extra spend
Use a normal prompt when the task is short, exploratory, highly subjective, or waiting on human judgment.
The point is to stop supervising the work that can be checked, and save your attention for the work that genuinely can't.
5. Before your first run
Before setting a goal, answer these:
What exact artifact should exist at the end?
What must be true about it, in terms a stranger could confirm?
What evidence proves those conditions, visible in the conversation?
What should the agent do when it hits something it can’t get past?
What still requires my judgment, and shouldn’t be in the goal at all?
Then ask the agent to critique the goal before it starts. It’ll usually find an impossible condition or a missing test before the expensive loop begins. Some of my best runs started with the model rewriting my own goal tighter than I’d written it.
A few things I wish I’d known earlier:
Set a turn cap. 20 to 40 turns covers most real work. A slightly wrong condition loops until you kill it by hand, and you won’t be watching. Set it before you start, not after you notice it’s been running for two hours.
Let the model write the goal. Ask Claude to draft the
/goalprompt. It almost always writes a more checkable finish line than you’d write on the first try.Stop treating it as a coding thing. Research, notes cleanup, trip planning, audits. None of that is code. Box it into technical work and you leave most of the value sitting there.
Constraints close the shortcuts. The agent takes the shortest path to your condition, which is sometimes the path you didn’t want. “Do not guess. Do not use placeholders. Do not quietly skip items.” These lines go into almost every goal I write now.
The command takes ten seconds to learn. The thing that takes longer is writing down what finished means before you walk away, in words a checker can confirm without reading your mind.
Build that habit and you stop being the thing that keeps the work moving. You come back to work that was checked by something other than the thing that did it.
Everyone else is still in the chair, typing “keep going,” or trusting a “done” they shouldn’t.
That’s all for today. See you next week,
Aakash
P.S. Want my AI tool stack? Join my bundle. Want my job search coaching? Apply to my cohort.
Yes they can be great when used properly. I created my own goal readiness packet skill to ensure the ideal structure for a goal and that way they are always have a standardized and validated structure to ensure they consistently perform as intended. Speeds up the process. Adds one extra ceremonial step but it's worth it.
https://github.com/iAAi33iAAi