
Amazon’s AI Chip Bet: AI Update #8
Plus: What you need to know about the launch of Gemini 3 flash
👋 Hey there, I’m Aakash. In this newsletter, I cover AI, AI PM, and getting a job. This is your weekly AI update. For more: Podcast | Cohort
Annual subscribers get a free year of 9 premium products: Dovetail, Arize, Linear, Descript, Reforge Build, DeepSky, Relay.app, Magic Patterns, and Mobbin (worth $28,336).
Welcome back to the AI Update.
Google just made a top-3 frontier model free for billions of users with the launch of Gemini 3 Flash. Their stock is up 57% this year. They now own two of the top three spots on every major leaderboard.
Everyone’s talking about Google’s AI dominance.
Almost no one is talking about the company that might be the most undervalued AI play in tech right now. Their stock is up 1% this year. And I think the market has it completely wrong.
That’s today’s deep dive.
Plus, I cover all the AI news you need to know from the week.
Finally, I end with a recap of my sit down with Axel Sooriah on my 6-steps to AI PM.

Product Faculty: In-Person AI PM Certificate

In 2024, when AI PM was becoming a thing, I dropped into this course by Miqdad Jaffer. Since then, the course has transformed and iterated to the #1 AI PM Certificate, with over 758 reviews.
There’s nowhere else to get its combination of in-person Build Labs (with Pawel Huryn) and content (from an OpenAI product leader).

Top News this Week: Gemini Flash Expands the Pareto Frontier
Look at the LMArena rankings right now for text:
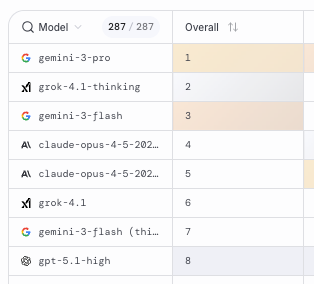
Gemini 3 Pro (Google)
Grok 4.1 Thinking (xAI)
Gemini 3 Flash (Google)
...
GPT-5.1-high (OpenAI)
Google holds two of the top three spots. OpenAI’s best model sits at #8. And yesterday, Google made the #3 model free for everyone.
Free you say?
Yes.
Gemini 3 Flash is now the default across the Gemini app and AI Mode in Search globally. Billions of users just got access to a top-3 frontier model at no cost.
The benchmarks back it up: 90.4% on GPQA Diamond (PhD-level reasoning), 81.2% on MMMU Pro, 78% on SWE-bench Verified. It’s 3x faster than 2.5 Pro while using 30% fewer tokens on average.
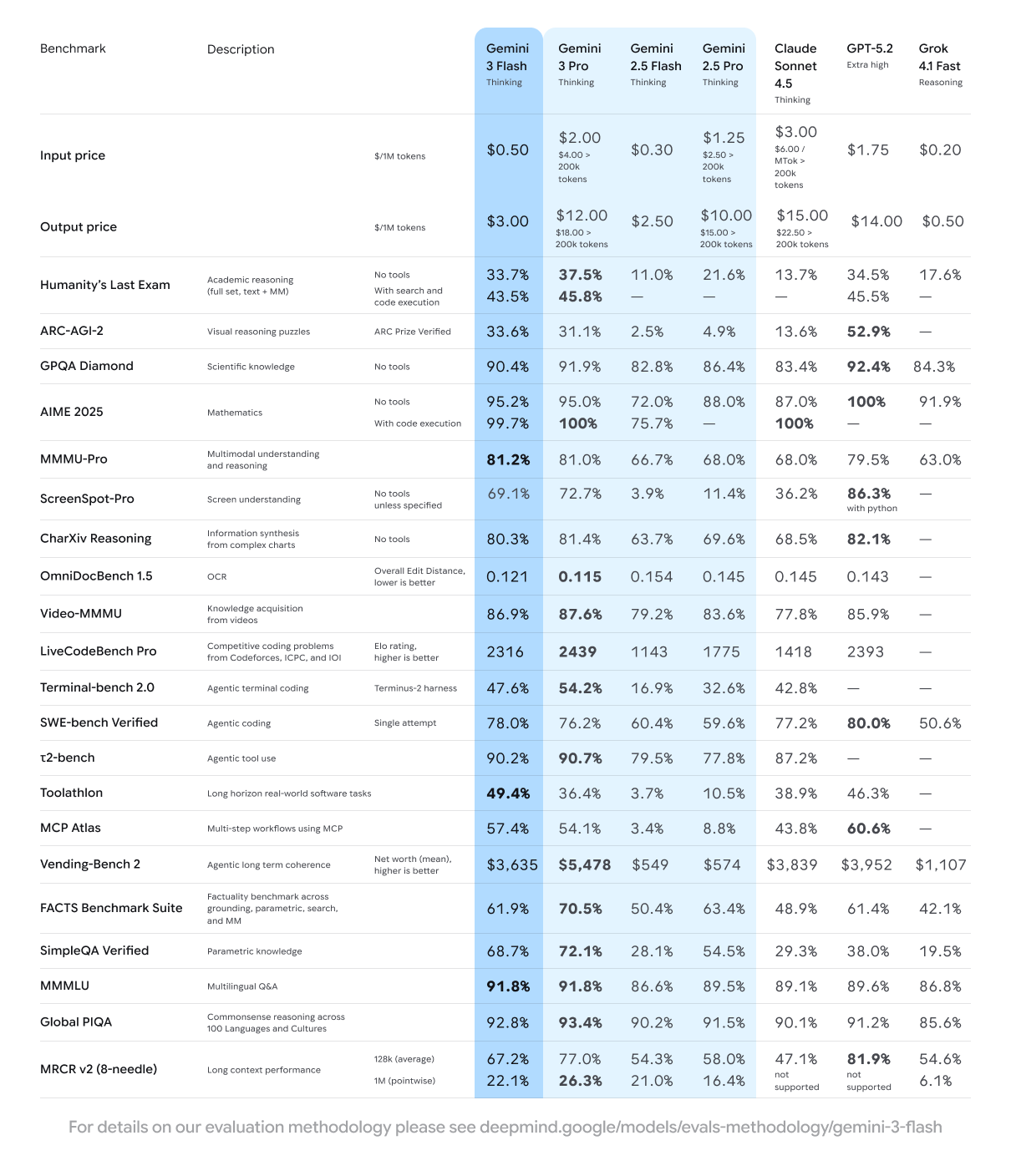
For developers, the pricing is $0.50/1M input tokens and $3/1M output tokens. JetBrains, Figma, Cursor, Replit, and Bridgewater are already using it for production workloads.
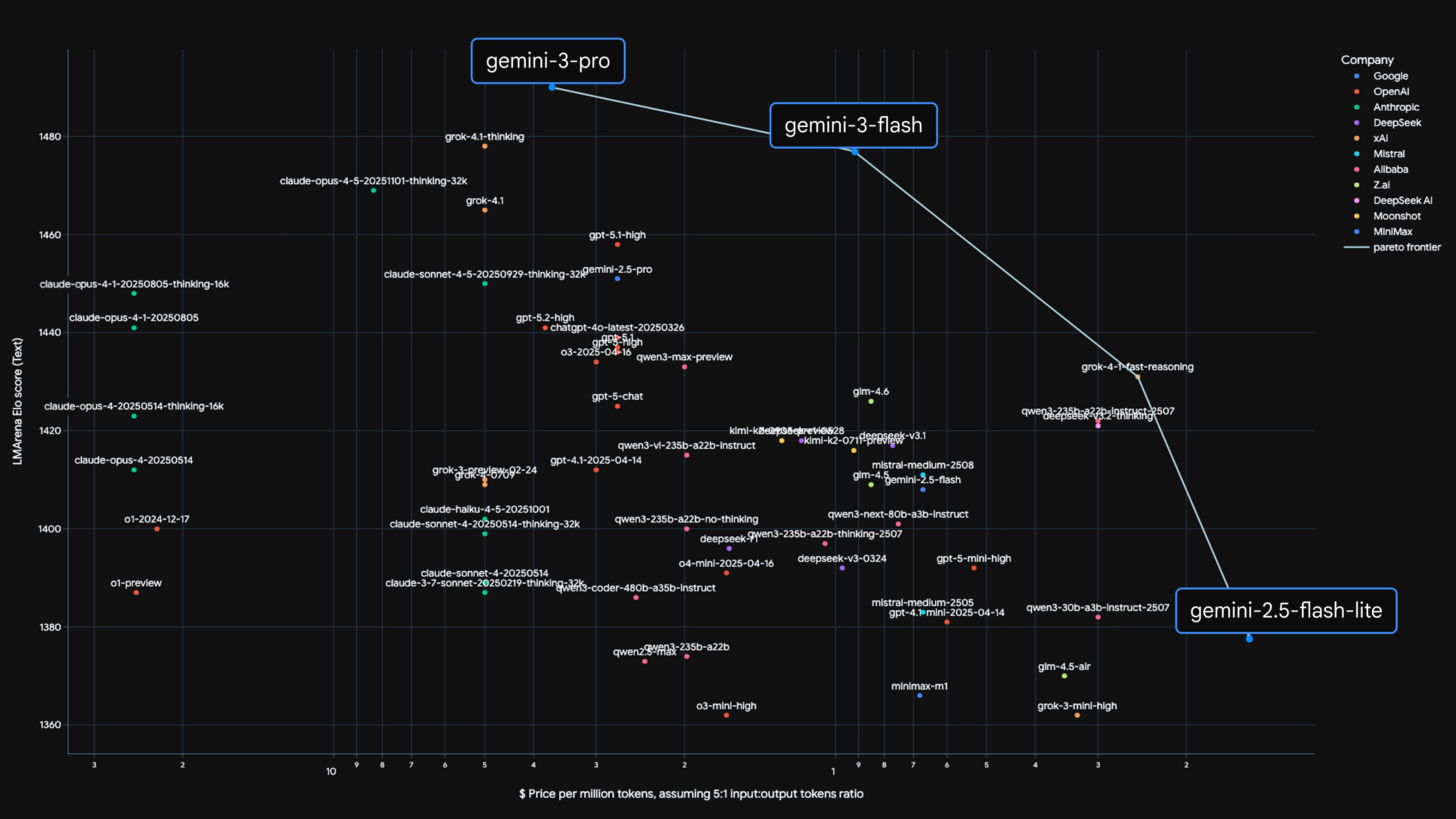
For two years, the AI race has been about who has the smartest model. Google just changed the question. When frontier intelligence is free and distributed through Search, Android, Chrome, and Workspace, the race becomes about reach.
Google now has both.

There’s a million AI news articles, resources, tools, and fundraises every week. Here’s what mattered:
News
OpenAI shipped GPT Image 1.5 + launched an app store for ChatGPT with task-specific mini-apps for cooking, fitness, coding, and more.
Apple joined Hugging Face Enterprise and released Sharp, a model that turns images into 3D splats. Apple now has 150+ models on HF.
Elon Musk said lunar mass drivers will make “money irrelevant” - the 50-year-old tech could throw 600,000 tons of material per year into space at near-zero marginal cost.
Resources
John Schulman on scaling RL and building AI labs
How Descript builds AI features users actually use
Can AI run a business?
New Tools
NexaSDK: Easiest solution to deploy multimodal AI to mobile hit #1 on PH
Google Vids: AI video creation for work hit #1 on PH
Market
Coursera is acquiring Udemy in a $2.5B all-stock deal as both platforms race to own AI workforce reskilling.
OpenAI is targeting a $830B valuation in its next round, with Amazon potentially investing $10B and raising $100B overall
And now on to today’s deep dive:

Amazon’s AI Chip Bet
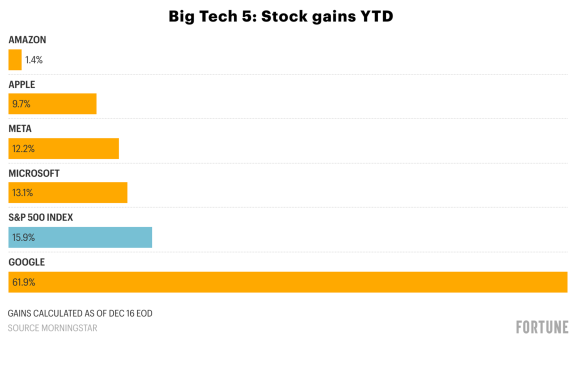
Amazon’s stock has barely moved this year.
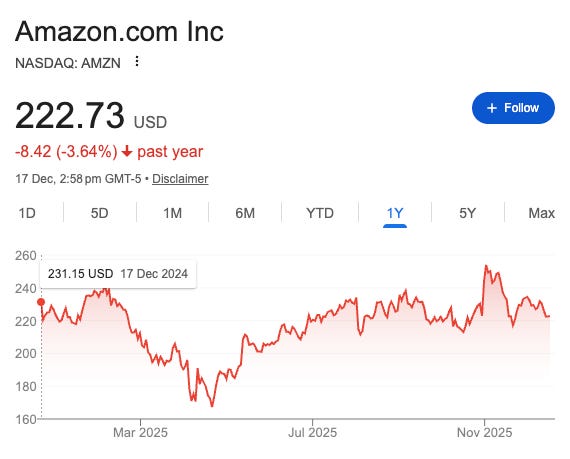
Google is up ~57%. The S&P 500 is up ~16%. Microsoft, Apple, and Meta are each around ~10-13%.
Amazon? 1%.
The narrative on Wall Street: Amazon missed the AI wave. They’re behind Google. They’re behind Microsoft. Their chips can’t compete with Nvidia.
Here’s where I land: The market is severely underestimating Amazon’s AI strategy. And the $350M acquisition that makes it all possible, Annapurna Labs back in 2015, will go down as one of the best acquisitions in tech history.
And that’s today’s deep dive:
Why Amazon’s stock is lagging (and why the market is wrong)
Trainium3 performance, costs, and limitations
Trainium4 prospects vs Nvidia
How Amazon stacks up against Blackwell and TPU
The Annapurna Labs story - a $350M bet that changed everything
1. Why Amazon’s stock is lagging (and why the market is wrong)
Let’s start with the stock performance, because the numbers are brutal.
Amazon delivered a 1% return in 2025 while Google surged 57%. That’s the worst performance among the Mag 7 by a wide margin.
The conventional explanation is Amazon doesn’t have an AI story. Google has Gemini 3 and TPUs. Microsoft has OpenAI + Copilot. Meta has MSL. Amazon has... Alexa?
But this explanation misses what’s actually happening inside AWS.
Three things the market is underweighting:
AWS still dominates cloud. AWS accounts for over 57% of Amazon’s operating profits. It runs at 36% margins. That’s the profit engine funding everything else.
Anthropic trains on Amazon’s chips. Project Rainier, Anthropic’s training cluster, runs on hundreds of thousands of Trainium chips. One of the two frontier AI labs uses Amazon’s silicon regularly (in some workloads).
Trainium3 just shipped. This month at re:Invent 2025, AWS launched its first 3nm AI chip. At the rack level, it matches Nvidia’s GB300 NVL72 on FP8 performance.
The market sees a lagging stock. I see a company that’s been quietly building the infrastructure to compete at the frontier.
2. Inside Trainium3: Performance, Costs, and Limitations
Let me break down what Trainium3 actually delivers.

Performance
Each Trainium3 chip produces 2.5 petaFLOPS of FP8 compute. That’s roughly 2x what Trainium2 delivered and puts single-chip performance ahead of Nvidia’s H100/H200, but behind Blackwell’s B200.
The memory specs are solid: 144GB of HBM3E with 4.9 TB/s of bandwidth. AWS achieved a 70% increase in memory bandwidth by switching from Samsung’s HBM (which ran at slower 5.7Gbps pin speeds) to Hynix and Micron running at 9.6Gbps, the highest HBM3E speeds we’ve seen.
The real story is the rack.
AWS’s Trn3 UltraServer packs 144 Trainium3 chips into a single liquid-cooled rack, delivering 0.36 ExaFLOPS of FP8 performance. That matches Nvidia’s GB300 NVL72.
With sparsity enabled, that number climbs to 1.4 ExaFLOPS. Trainium3’s hardware can leverage 16:4 structured sparsity to quadruple effective throughput on supported workloads.
Costs
AWS hasn’t published direct pricing comparisons, but here’s what we know:
AWS claims Trainium delivers 30-40% better price-performance than comparable Nvidia instances. Gadi Hutt, AWS’s Senior Director, told CNBC that Trainium provides “up to 40% price gain compared to AI-GPU on the market.”
The cost advantage comes from three places:
Process efficiency. Trainium3 is the first dedicated ML accelerator built on 3nm. AWS claims 40% better energy efficiency than Trainium2.
Vertical integration. Amazon designs the chips (via Annapurna), manufactures through TSMC, and deploys on their own cloud. No middleman margins.
Scale. AWS can link thousands of UltraServers together, supporting up to 1 million Trainium3 chips in a single deployment. That’s 10x the previous generation.
For context, Project Rainier for Anthropic spans hundreds of thousands of chips and consumes over a gigawatt of power. That’s enough to power a small city. And Anthropic chose Trainium over Nvidia.
The power numbers reinforce the cost story. Trainium3 runs at roughly 1,000W per chip. Nvidia’s GB300 runs at 1,400W. That’s 40% less power draw at comparable rack-level performance.
Some customers are seeing even steeper savings. Industry reports suggest Trainium instances run around $1/hour compared to $3/hour for H100s. With long-term contracts, that can drop to $0.50/hour. That’s 1/6th the cost of Nvidia.
Limitations
Now for what Trainium3 can’t do yet.
Software maturity is the biggest gap. Nvidia’s CUDA (Compute Unified Device Architecture) ecosystem has a decade head start. Developers think in PyTorch and CUDA. Switching to Amazon’s Neuron SDK requires optimization work.
AWS is trying to close this gap by open-sourcing its stack:
Phase 1: Native PyTorch backend and NKI (Neuron Kernel Interface) compiler
Phase 2: XLA graph compiler and JAX stack
But here’s the catch: full LNC=8 support won’t arrive until mid-2026. LNC (Logical NeuronCore) configuration is what most ML researchers want for experimentation. Until then, Trainium3 is optimized for production workloads at companies with elite kernel engineers, like Anthropic.
The other limitation is single-chip performance. At 2.5 petaFLOPS, Trainium3 sits behind Nvidia’s Blackwell (~5 petaFLOPS) and Google’s Ironwood (4.6 petaFLOPS) on raw FP8 compute. Amazon makes up for this with scale, packing more chips per rack, but the gap exists.
There’s one more gap worth noting: FP4 inference.
At ultra-low precision, Nvidia’s GB300 leads by roughly 3x. This matters because AI labs are aggressively adopting FP4 for inference. It lets massive models fit on fewer chips, cutting cost per token dramatically.
Amazon knows where the gap is. That’s exactly why Trainium4 will deliver 6x FP4 performance. They’re not ignoring the problem. They’re shipping the fix.
3. Trainium4: The Nvidia-Compatible play coming next December
The Trainium4 announcement is where Amazon’s strategy gets interesting.

AWS revealed that Trainium4 will support Nvidia’s NVLink Fusion interconnect. This means Trainium4 chips, Graviton CPUs, and Nvidia GPUs will be able to communicate within the same rack architecture.
Why this is a strategic pivot:
For years, hyperscalers have been building custom silicon to escape Nvidia’s margins. Google has TPUs. Amazon has Trainium. Meta is building MTIA (Meta Training and Inference Accelerator). The playbook: vertical integration, walled gardens, chip independence.
Amazon just changed course.
By adopting NVLink Fusion, AWS is acknowledging something important: Nvidia’s ecosystem is too entrenched to ignore. CUDA has become the default. Developers don’t want to rewrite their training code. And enterprises want optionality, the ability to mix Nvidia GPUs with cheaper alternatives depending on the workload.
Nvidia’s blog post on the partnership made the strategy explicit:
By leveraging NVLink Fusion for Trainium4 deployment, AWS will drive faster innovation cycles and accelerate time-to-market.
WinBuzzer called it “a tacit admission that Nvidia’s ecosystem dominance is currently insurmountable.”
I see it differently. Amazon is playing the long game. Instead of trying to replace Nvidia overnight, they’re positioning AWS as the infrastructure layer that makes multi-vendor AI deployments viable. Win the rack, even if you don’t win every chip.
Trainium4 Specs (Projected)
AWS promises significant improvements over Trainium3:
3x FP8 performance (at least)
6x FP4 performance
4x more memory bandwidth
8 stacks of HBM4 (doubling memory capacity)
There will be two development tracks running in parallel:
UALink track: Industry-standard interconnect
NVLink track: Nvidia’s proprietary interconnect
The timeline: Late 2026, probably announced at re:Invent 2026. The NVLink track may slip due to integration complexity, as most of Nvidia’s mixed-signal engineers will be focused on their own Vera Rubin launch.
4. How Amazon stacks up against Blackwell and TPU
The AI chip landscape now has three serious custom silicon players: Amazon (Trainium), Google (TPU), and Nvidia (Blackwell).
Here’s how they compare:
Single-Chip Performance (FP8)
Nvidia and Google lead on single-chip performance. Trainium3 lags by roughly 2x on paper.
Rack-Scale Performance
At the rack level, Amazon matches Nvidia. But Google pulls away dramatically with Ironwood pods that can scale to 9,216 chips in a single compute domain, delivering 42.5 ExaFLOPS.
Google achieves this with optical circuit switches and a 3D torus topology that eliminates the need for expensive NVLink-style switches.
Total Cost of Ownership
This is where the real comparison matters.
SemiAnalysis estimates Google’s all-in TCO per Ironwood chip is roughly 44% lower than Nvidia’s GB200 in equivalent configurations.
AWS claims Trainium delivers 30-40% better price-performance than comparable Nvidia instances.
Both custom silicon players beat Nvidia on cost. The question is whether the software overhead erases those savings.
For teams with elite ML engineers who can optimize kernels, the answer is no. Trainium and TPU deliver real cost advantages.
For teams that need to move fast and think in PyTorch, Nvidia’s CUDA ecosystem still commands a premium.
Software Maturity
Here’s the thing most people miss about Nvidia: the moat isn’t just silicon, it’s mostly software.
CUDA has been around since 2006. That’s nearly two decades of developers writing kernels, building libraries, and shipping production code on Nvidia’s stack. Every PyTorch tutorial assumes CUDA. Every ML course teaches on GPUs. The ecosystem isn’t something Nvidia built alone. It’s something millions of developers built for them, one commit at a time.
That’s the real lock-in. You can build a faster chip. You can’t easily rebuild an ecosystem.
AWS understands this. That’s why they’re not just shipping Trainium chips. They’re open-sourcing the entire software stack: PyTorch backend, kernel compiler, JAX support. The bet is that if you make it easy enough to port code, developers will follow the economics.
It’s a long game. But it’s the right game.
5. The Annapurna Labs Story: A $350M Bet That Changed Everything
In January 2015, Amazon acquired Annapurna Labs, an Israeli chip startup, for $350 million.

At the time, the acquisition barely made headlines. Annapurna had around 150 engineers building custom chips for networking and storage. Amazon’s stated goal was to reduce its dependence on Intel for server processors.
A decade later, that $350M bet has produced:
Graviton: Amazon’s custom ARM-based CPUs, now powering a significant portion of AWS compute
Inferentia: Amazon’s inference chips
Trainium: Amazon’s training chips, now powering Anthropic’s frontier models
Gadi Hutt, who leads product and customer engineering for Annapurna, told The Register that Trainium3 is “the most powerful AWS chip created to date.”
The acquisition math is staggering.
For context, Nvidia trades at a market cap of over $4 trillion. Broadcom, which designs Google’s TPUs, trades at over $1 trillion. Amazon bought the team that’s now building competitive AI silicon for $350 million, less than what some AI startups raise in a Series B.

Stratechery noted the strategic implications:
AWS has the largest cloud and the weakest AI offerings; Google, meanwhile, is heavily invested in AI as a cloud differentiator, and Microsoft has exclusive rights to OpenAI IP.
But “weakest AI offerings” misses what Annapurna has built. The team that designed Trainium is the same team that’s now shipping rack-scale systems matching Nvidia’s best.
The market prices Amazon like it’s behind in AI. The Annapurna Labs acquisition tells a different story.
The Bottom Line
The stock says Amazon is behind. The chips say otherwise.
Trainium3 matches Nvidia’s GB300 NVL72 at the rack level on FP8 performance. It’s the first 3nm AI accelerator. And it’s already powering Anthropic’s frontier models.
Trainium4 will support Nvidia’s NVLink Fusion, making AWS the infrastructure layer for multi-vendor AI deployments. Instead of trying to replace Nvidia, Amazon is positioning itself as the platform that gives customers choice.
The Annapurna Labs acquisition for $350M in 2015 will go down as one of the best acquisitions in tech history. That team has produced three generations of custom chips and is now competing at the frontier.
The market is pricing Amazon like they missed the AI wave. I think they’re reloading.
Finally, onto insights from a webinar I did:

The 6-Step Path to Building with AI
I joined Axel Sooriah on Product in Practice by Atlassian to break down how PMs can actually build with AI.
Most PMs know they should be building with AI. Few have a clear progression to get there.
Here’s the 6-step path I walked Axel through:
1/ Know yourself.
What scares you most about AI building? Is it opening an IDE and staring at code that feels like the Matrix? Is it understanding what transformers do? How RAG works?
Figure out your deficiency first.
If I asked you “what are the different architectures an AI agent could have?” and you can’t answer, you’ll struggle to build AI agents. Start there.
2/ Shape your content diet.
Things move so fast that books don’t work anymore. The best people doing this are on Twitter and LinkedIn. Follow them. Make AI your feed.
3/ Start with prototyping.
Pick something you’re passionate about. Maybe fantasy sports. Build something in Lovable, Bolt, or V0 that tracks injuries and alerts you when someone on your team goes down.
Keep it internal. Keep it fun.
Then you’ll hit a limit. Maybe you want the agent to automatically move the injured player out of your lineup. That brings you to the next step.
4/ Graduate to workflows.
Use n8n, Lindy, Make.com, or Relay.app to chain together a full workflow. You’re moving from prototype to end-to-end system. No code required yet.
5/ Move to code.
Open Cursor or Windsurf. Rebuild what you made in the no-code builder, but now in actual code.
If code is your biggest weakness, do this earlier. For most people, this progression works.
6/ Take it to work.
Build a real agentic AI feature into your product. Connect to MCPs. Ship it.
Here’s the thing: just about every product in the world could be enhanced with AI. But don’t sprinkle AI on top. Go to the core problems you’re solving and add AI to help people do what they’re already trying to do.
We also covered:
How to raise AI fluency across your org as a leader
Why we could enter “the golden age of the feature factory” if we prototype before we investigate
The parallel prototyping workflow I use across Bolt, Lovable, and V0
That’s all for today. See you next week,
Aakash
P.S. You can pick and choose to only receive the AI update, or only receive Product Growth emails, or podcast emails here.